Shannon information, compression and psychic powers
Fun thing I found in the J-list, a game of code golf. Generate the following pattern with the least number of bytes of code:
_____*_____
_____*_____
____*_*____
___*___*___
__*_____*__
**_______**
__*_____*__
___*___*___
____*_*____
_____*_____
_____*_____
The J solution by Marshall Lochbaum is the best one I’ve seen, taking only 18 bytes of code.
'_*'{~4=+/~ 4<.|i:5
I’ll break this down into components for the folks who don’t speak J, so you can see what’s going on:
i:5 NB. -5 to 5;
_5 _4 _3 _2 _1 0 1 2 3 4 5
|i:5 NB. make the list positive
5 4 3 2 1 0 1 2 3 4 5
4<.|i:5 NB. cap it at 4
4 4 3 2 1 0 1 2 3 4 4
+/~ 4<.|i:5 NB. ~ is magic which flips the result around and feeds it to the NB. verb immediately to the left. NB. the left hand +/ verb is the + operator applied / across the NB. list
8 8 7 6 5 4 5 6 7 8 8
8 8 7 6 5 4 5 6 7 8 8
7 7 6 5 4 3 4 5 6 7 7
6 6 5 4 3 2 3 4 5 6 6
5 5 4 3 2 1 2 3 4 5 5
4 4 3 2 1 0 1 2 3 4 4
5 5 4 3 2 1 2 3 4 5 5
6 6 5 4 3 2 3 4 5 6 6
7 7 6 5 4 3 4 5 6 7 7
8 8 7 6 5 4 5 6 7 8 8
8 8 7 6 5 4 5 6 7 8 8
4=+/~ 4<.|i:5 NB. Which of these is equal to 4?
0 0 0 0 0 1 0 0 0 0 0
0 0 0 0 0 1 0 0 0 0 0
0 0 0 0 1 0 1 0 0 0 0
0 0 0 1 0 0 0 1 0 0 0
0 0 1 0 0 0 0 0 1 0 0
1 1 0 0 0 0 0 0 0 1 1
0 0 1 0 0 0 0 0 1 0 0
0 0 0 1 0 0 0 1 0 0 0
0 0 0 0 1 0 1 0 0 0 0
0 0 0 0 0 1 0 0 0 0 0
0 0 0 0 0 1 0 0 0 0 0
'_*'{~4=+/~ 4<.|i:5
NB. { is an array selector, ~ pops the previous result in 1's
NB. and 0's in front of the string '_*', which creates the
NB. required array of characters and voila!
_____*_____
_____*_____
____*_*____
___*___*___
__*_____*__
**_______**
__*_____*__
___*___*___
____*_*____
_____*_____
_____*_____
I asked some facebook pals for a solution, and got some neat ones:
Python from Bram in 94 bytes:
for i in range(-5,6):print ''.join(['*_'[min(abs(i),4)+min(abs(j),4)!=4] for j in range(-5,6)])
A clever 100 byte Perl solution from Mischa (to be run with -Mbigint):
for$i(0..10){print($_%12==11?"\n":1<<$i*11+$_&41558682057254037406452518895026208?'*':'_')for 0..11}
Some more efficient solutions by Mischa in perl and assembler.
Do feel free to add clever solutions in the comments! I’d like to see a recursive solution in an ML variant, and I’m pretty sure this can be done in only a few C characters.
It’s interesting in that the display of characters is only 132 bytes (counting carriage returns, 121 without), yet it is hard in most languages to do this in under 100 bytes. The winner of the contest used a 73 byte shell script with gzipped contents attached. Pretty good idea and a praiseworthy hack. Of course, gzip assumes any old kind of byte might need to be packed, so it’s not the post efficient packing mechanism for this kind of data.
This gets me to an interesting point. What is the actual information content of the pattern? Claude Shannon told us this in 1948. The information content of a character in a string is approximately
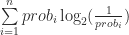
If you run this string through a gizmo for calculating Shannon entropy (I have one in J, but use the R infotheo package), you’ll find out that it is completely specified by 3 bits sent 11 times, for a total of 33 bits or 4.125 bytes. This sounds completely insane, but look at this coding for the star pattern:
000 _____*_____
000 _____*_____
001 ____*_*____
010 ___*___*___
011 __*_____*__
100 **_______**
011 __*_____*__
010 ___*___*___
001 ____*_*____
000 _____*_____
000 _____*_____
So, if you were to send this sucker on the wire, an optimal encoding gives 33 bits total. Kind of neat that the J solution is only 144 bits. It is tantalizing that there are only 5 distinct messages here, leaving room for 3 more messages. The Shannon information calculation notices this; if you do the calculation, it’s only 2.2 bits. But alas, you need some kind of wacky pants quantum computer that hasn’t been invented yet to send fractions of bits, so you’re stuck with a 3 bit code.
The amount of data that can be encoded in a bit is generally underestimated. Consider the 20 question game. Go click on the link. it’s a computer program that can “read your mind.” It’s an extremely clever realization of Shannon information for a practical purpose. The thing can guess what you’re thinking about by asking you 20 questions. You only give it 20 bits of information, and it knows what you’re thinking about. The reason this is possible is 20 bits is actually a huge amount of information. If you divide the universe of things a person can think of into 2^20 pieces, each piece is pretty small, and is probably close enough to something it seems like the machine can read your mind. This is also how “mentalism” and psychic powers work. Psychics and Mentalists get their bits by asking questions, and either processing the answers, or noticing the audience reaction when they say something (effectively getting a bit when they’re “warm”). Psychics and TV mentalists also only have to deal with a limited number of things people are worried about when they talk to psychics and TV mentalists.
Lots of machine learning algorithms work like optimal codes, mentalists and the 20 questions game. Decision trees, for example. Split the universe of learned things into a tree, which is effectively 1’s and 0’s (and of course, the split criterion at each node).
It’s little appreciated that compression algorithms are effectively a form of decision tree. In fact, they’re pretty good as decision trees, in particular for “online” learning, and sequence prediction. Look at a recent sequence, see if it’s like any past sequences. If it is a novel sequence, stick it in the right place in the compression tree. If it occurred before, you know what the probability of the next character in the string is by traversing the tree. Using such gizmos, you can generate artificial sequences of characters based on what is in the tree. If you encode “characters” as “words,” you can generate fake texts based on other texts. If you encode “characters” as “musical notes” you can generate fake Mozart based on Mozart. There are libraries out there which do this, but most folks don’t seem to know about them. I’ve noodled around with Ron Begleiter’s VMM code which does this (you can find some primitive R hooks I wrote here) to get a feel for it. There’s another R package called VLMC which is broadly similar, and another relative in the PST package.
One of the interesting properties of compression learning is, if you have a good compression algorithm, you have a good forecasting algorithm. Compression is a universal predictor. You don’t need to do statistical tests to pick certain models; compression should always work, assuming the string isn’t pure noise. One of the main practical problems with them is picking a discretization (discretizations … can also be seen or used as a ML algorithm). If the data is already discrete, a compression algorithm which compresses well on that data will also forecast well on the data. Taking this a step further into crazytown, one can almost always think of a predictive algorithm as a form of compression. If you consider something like EWMA, you’re reducing a potentially very large historical time series to one or two numbers.
While the science isn’t well established yet, and it certainly isn’t widely known (though the gizmo which guesses what google search you’re going to do is a prefix tree compression learner), it looks like one could use compression algorithms to do timeseries forecasting in the general case, hypothesis testing, decryption, classification, regression and all manner of interesting things involving data. I consider this idea to be one of the most exciting areas of machine learning research, and compression learners to be one of the most interesting ways of thinking about data. If I free up some time, I hope to write more on the subject, perhaps using Ron’s code for demonstrations.
Fun people to google on this subject:
Boris Ryabko & Son (featured in the ants thing)
The ubiquitous Thomas Cover

Speaking of predictors: http://www.loper-os.org/bad-at-entropy/manmach.html
(Good illustration of the concept, for the “peanut gallery.” Believe it or not, I posted it and thousands are still “playing.”)
I think that gizmo is one of Shannon’s original guessing games.
Do you have the source handy? I’d love to find the ‘one true’ origin of the algo.
If you google around on “Shannon guessing game” it gives some similar examples. I am vaguely recalling from one of his bios that he made a hardware implementation of the guessing game you coded up. Anyway, it was certainly an information theory guy who came up with the concept.
Main thing to Google is Kolmogorov complexity.
Correct me if I am wrong: are there not proofs (or at least arguments) that Kolmogorov complexity asymptotically converges to Shannon information? I vaguely recall reading this at some point, but google fails me.
I’d be surprised, as they’re measuring two different things. Entropy assumes that they’re just unstructured bits (air molecules flying around a room, etc.) while Kolmogorov complexity assumes some kind of underlying structure that the program is capturing. The difference gets existential when you start asking “what is randomness?”
Actually, I found the reference I was thinking of.
http://www.mdpi.com/1099-4300/13/3/595/pdf
“Kolmogorov complexity and Shannon entropy are conceptually different, as the former is based on
the length of programs and the later in probability distributions. However, for any recursive probability
distribution (i.e., distributions that are computable by a Turing machine), the expected value of the
Kolmogorov complexity equals the Shannon entropy, up to a constant term depending only on the
distribution (see [1]).”
I was mixing it up a bit in this essay, but more or less assuming this was true. I guess in this case, it is more or less true, as that pattern is certainly computable by Turing machines.
I ran across an article recently which illustrated the connection between information theory, renormalization and predictive modeling as well and simply as I’d found anywhere:
http://arxiv.org/abs/1303.6738
This is a cool connection. I believe the field is called Minimum Description Length (https://en.wikipedia.org/wiki/Minimum_description_length).
Great article. I recall many years ago reading and article that compression was being used to identify unknown authors. The better the compression of two “chunk” of text, the more likely the author. In other words 1MB of Melville compressed with another 1MB of Melville would be smaller than 1MB of Melville and 1MB of Chaucer. Now I understand why.
[…] techniques like LZW, and has deep roots in information theory and signal processing. Really, Claude Shannon wrote the first iterations of this idea. I can’t give you a good reference for this subject […]
[…] techniques like LZW, and have deep roots in information theory and signal processing. Really, Claude Shannon wrote the first iterations of this idea. I can’t give you a good reference for this subject in […]