Predicting with confidence: the best machine learning idea you never heard of
One of the disadvantages of machine learning as a discipline is the lack of reasonable confidence intervals on a given prediction. There are all kinds of reasons you might want such a thing, but I think machine learning and data science practitioners are so drunk with newfound powers, they forget where such a thing might be useful. If you’re really confident, for example, that someone will click on an ad, you probably want to serve one that pays a nice click through rate. If you have some kind of gambling engine, you want to bet more money on the predictions you are more confident of. Or if you’re diagnosing an illness in a patient, it would be awfully nice to be able to tell the patient how certain you are of the diagnosis and what the confidence in the prognosis is.
There are various ad hoc ways that people do this sort of thing. The one you run into most often is some variation on cross validation, which produces an average confidence interval. I’ve always found this to be dissatisfying (as are PAC approaches). Some people fiddle with their learners and in hopes of making sure the prediction is normally distributed, then build confidence intervals from that (or for the classification version, Platt scaling using logistic regression). There are a number of ad hoc ways of generating confidence intervals using resampling methods and generating a distribution of predictions. You’re kind of hosed though, if your prediction is in online mode. Some people build learners that they hope will produce a sort of estimate of the conditional probability distribution of the forecast; aka quantile regression forests and friends. If you’re a Bayesian, or use a model with confidence intervals baked in, you may be in pretty good shape. But let’s face it, Bayesian techniques assume your prior is correct, and that new points are drawn from your prior. If your prior is wrong, so are your confidence intervals, and you have no way of knowing this. Same story with heteroscedasticity. Wouldn’t it be nice to have some tool to tell you how uncertain your prediction when you’re not certain of your priors or your algorithm, for that matter?

Well, it turns out, humanity possesses such a tool, but you probably don’t know about it. I’ve known about this trick for a few years now, through my studies of online and compression based learning as a general subject. It is a good and useful bag of tricks, and it verifies many of the “seat of the pants” insights I’ve had in attempting to build ad-hoc confidence intervals in my own predictions for commercial projects. I’ve been telling anyone who listens for years that this stuff is the future, and it seems like people are finally catching on. Ryan Tibshirani, who I assume is the son of the more famous Tibshirani, has published a neat R package on the topic along with colleagues at CMU. There is one other R package out there and one in python. There are several books published in the last two years. I’ll do my part in bringing this basket of ideas to a more general audience, presumably of practitioners, but academics not in the know should also pay attention.
The name of this basket of ideas is “conformal prediction.” The provenance of the ideas is quite interesting, and should induce people to pay attention. Vladimir Vovk is a former Kolmogorov student, who has had all kind of cool ideas over the years. Glenn Shafer is also well known for his co-development of Dempster-Shafer theory, which is a brewing alternative to standard measure-theoretic probability theory which is quite useful in sensor fusion, and I think some machine learning frameworks. Alexander Gammerman is a former physicist from Leningrad, who, like Shafer, has done quite a bit of work in the past with Bayesian belief networks. Just to reiterate who these guys are: Vovk and Shafer have also previously developed a probability theory based on game theory which has ended up being very influential in machine learning pertaining to sequence prediction. To invent one new form of probability theory is clever. Two is just showing off! The conformal prediction framework comes from deep results in probability theory and is inspired by Kolmogorov and Martin-Lof’s ideas on algorithmic complexity theory.

The advantages of conformal prediction are many fold. These ideas assume very little about the thing you are trying to forecast, the tool you’re using to forecast or how the world works, and they still produce a pretty good confidence interval. Even if you’re an unrepentant Bayesian, using some of the machinery of conformal prediction, you can tell when things have gone wrong with your prior. The learners work online, and with some modifications and considerations, with batch learning. One of the nice things about calculating confidence intervals as a part of your learning process is they can actually lower error rates or use in semi-supervised learning as well. Honestly, I think this is the best bag of tricks since boosting; everyone should know about and use these ideas.
The essential idea is that a “conformity function” exists. Effectively you are constructing a sort of multivariate cumulative distribution function for your machine learning gizmo using the conformity function. Such CDFs exist for classical stuff like ARIMA and linear regression under the correct circumstances; CP brings the idea to machine learning in general, and to models like ARIMA when the standard parametric confidence intervals won’t work. Within the framework, the conformity function, whatever may be, when used correctly can be guaranteed to give confidence intervals to within a probabilistic tolerance. The original proofs and treatments of conformal prediction, defined for sequences, is extremely computationally inefficient. The conditions can be relaxed in many cases, and the conformity function is in principle arbitrary, though good ones will produce narrower confidence regions. Somewhat confusingly, these good conformity functions are referred to as “efficient” -though they may not be computationally efficient.

The original research and proofs were done on so-called “transductive conformal prediction.” I’ll sketch this out below.
Suppose you have a data set 
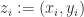

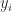


The conformal predictor 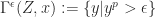

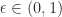
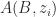

Example: If we have a forecast technique which works on exchangeable data, 

Simplifying the notation a little bit, let’s call 


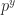

Practically speaking, this kind of transductive prediction is computationally prohibitive and not how most practitioners confront the world. Practical people use inductive prediction, where we use training examples and then see how they do in a test set. I won’t go through the general framework for this, at least this time around; go read the book or one of the tutorials listed below. For one it is worth, one of the forms of Inductive Conformal Prediction is called Mondrian Conformal Prediction; a framework which allows for different error rates for different categories, hence all the Mondrian paintings I decorated this blog post with.

For many forms of inductive CP, the main trick is you must subdivide your training set into two pieces. One piece you use to train your model, the proper training set. The other piece you use to calculate your confidence region, the calibration set. You compute the non-conformity scores on the calibration set, and use them on the predictions generated by the proper training set. There are
other blended approaches. Whenever you use sampling or bootstrapping in your prediction algorithm, you have the chance to build a conformal predictor using the parts of the data not used in the prediction in the base learner. So, favorites like Random Forest and Gradient Boosting Machines have computationally potentially efficient conformity measures. There are also flavors using a CV type process, though the proofs seem more weak for these. There are also reasonably computationally efficient Inductive CP measures for KNN, SVM and decision trees. The inductive “split conformal predictor” has an R package associated with it defined for general regression problems, so it is worth going over in a little bit of detail.
For coverage at 
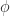


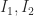
Train the learner using data on the proper training set
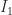

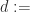

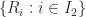


The prediction interval for a new point

This type of thing may seem unsatisfying, as technically the bounds on it only exist for one predicted point. But there are workarounds using leave one out in the ranking. The leave one out version is a little difficult to follow in a lightweight blog, so I’ll leave it up as an exercise for those who are interested to read more about it in the R documentation for the package.
Conformal prediction is about 10 years old now: still in its infancy. While forecasting with confidence intervals is inherently useful, the applications and extensions of the idea are what really tantalizes me about the subject. New forms of feature selection, new forms of loss function which integrate the confidence region, new forms of optimization to deal with conformal loss functions, completely new and different machine learning algorithms, new ways of thinking about data and probabilistic prediction in general. Specific problems which CP has had success with; face recognition, nuclear fusion research, design optimization, anomaly detection, network traffic classification and forecasting, medical diagnosis and prognosis, computer security, chemical properties/activities prediction and computational geometry. It’s probably only been used on a few thousand different data sets. Imagine being at the very beginning of Bayesian data analysis where things like the expectation maximization algorithm are just being invented, or neural nets before backpropagation: I think this is where the CP basket of ideas is at. It’s an exciting field at an exciting time, and while it is quite useful now, all kinds of great new results will come of it.
There is a website and a book. Other papers and books can be found in the usual way. This paper goes with the R package mentioned above, and is particularly clearly written for the split and leave one out conformal prediction flavors. Here is a presentation with some open problems and research directions if you want to get to work on something interesting. Only 19 packages on github so far.

Get your Conformal Predictions here.

I’m hazy on how this is different from simply evaluating the error on a validation set drawn from thetraining set (and seperate from the test set)
Because it’s defined for out of sample points, and it changes when your out of sample points have a lower or higher non-conformity score. So you know things like, “I am really sure of my prediction on THIS point, but not so much on THAT point.”
While this blog has introduced the idea to a broader audience, I confess it seems to have fallen well short of the mark. I’ll have to do another one with examples.
Jumping in late here — very late — a significant problem in machine learning contexts is “over-training”. Over-training is when we invest heavily in “improvements” which are not useful. These are artifacts of the training set which are just noise in larger contexts. But there’s no way of avoiding those except by going outside of the training set.
Hi, thank you for the detailed tour, yet I fail to understand the buttom line processs. Can you please share a pseudo code? Let’s say we use a random forest. How do you use the non used samples to predict the confidence? Moreover, in modern Deep Learning usually the output is already in probabilistic terms (softmax layer) so how and does this trick help? Last but not least, it seems like the output is in terms of p-value. How do you generalize to regression?
You can find code in my githubs and on CRAN.
Softmax layer is just an objective function for classifiers. It tells you nothing about the confidence the NN is correct (the CDF of the prior softmax fits would basically be CP).
For standard CP you pick the p-value, you get the prediction class or the null (can’t predict with p-value confidence) class. For regression you get a confidence interval.
It helps because you sometimes REALLY need to know if your classification is correct. What if it is a cancer prediction that will involve major surgery? Softmax won’t tell you a thing. CP will tell you how confident you are in your prediction. For trading, CP will tell you how much to bet.
Hi Scott, great article. One question: you say in the article, that “There are a number of ad hoc ways of generating confidence intervals using resampling methods and generating a distribution of predictions”, could you give some examples?
You could fit a logistic regression model to misclassifications and use that (Platt scaling). You could fit some arbitrary basket of subsets of data and look at the variance in a regression prediction and hope for the best. People have come up with lots of these things. You could use a Bayesian model that has this idea baked into it (but still depends on correct priors). CP has the benefit of being general and non-arbitrary.
hey Scott, thanks for this. Sorry if this is obvious, but can you please be more explicit and explain what’s wrong with building a second regression model on validation data residuals of the first model?
There’s nothing wrong with it, if you think your regression model explains the residuals or your probability of error. Conformal prediction comes with proofs of efficiency, and can be stacked up into learners with useful properties, like Mondrian classification or Venn prediction. There are a few papers out there with comparisons; I think some are here:
http://www.alrw.net/
I read in detail about conformal prediction for the first time here (then a PhD student). I had heard of it, but thought it was some obscure academic curiosity. But I do credit you for putting that brain-worm (wrote my first conformal paper recently). As you might have also noticed, conformal prediction is finally seeing some activity now. It is still barely known, but some bigwigs outside the group you mentioned have started writing papers on it now, which is honestly little bit surprising to me. It seems to have happened out of nowhere.
Can you point me towards the latest interesting things? I haven’t followed the literature closely; would be interested to know if anything important is going on, or what others make of it.
Congrats on your Ph.D.!
Sorry, I signed up for, but didn’t get a notification of a reply, so didn’t realize.
It is a bit tough to summarize the ideas in general, I think, without writing a post. 🙂
However, I would still say that the progress has been shallow compared to what is already present in the book by Vovk, Gammerman and Shafer – In the sense that it has largely focused on extending the older framework e.g. from marginal to “conditional” validity https://projecteuclid.org/journals/annals-of-statistics/volume-49/issue-1/Predictive-inference-with-the-jackknife/10.1214/20-AOS1965.full and https://academic.oup.com/imaiai/article-abstract/10/2/455/5896927, “conformalization” of some existing methods e.g. https://arxiv.org/abs/2103.09763 or https://arxiv.org/abs/1905.03222 or https://arxiv.org/abs/2006.06138, considering some scenarios beyond the original e.g. distribution shifts https://arxiv.org/abs/2106.00170 or distributional settings https://www.pnas.org/content/118/48/e2107794118; extensions to modern neural networks https://arxiv.org/abs/2110.09192 or https://arxiv.org/abs/2101.02703 structured losses https://arxiv.org/abs/2110.01052 or the paper I mentioned above https://arxiv.org/pdf/2106.00225.pdf (this simply proposes a really simple method that allows for approximately local validity). You already mentioned drug discovery — I have actually been seeing some uses of it in industry in that domain. Like you, Larry Wasserman was also proselytizing for such methods (but in the context of Bayesian models) https://arxiv.org/abs/1202.0633, the group at Oxford got their hint and proposed a variant for Bayesian models (with the posterior predictive density being the conformity score) https://arxiv.org/abs/2106.06137
Despite my comment re: shallow, I think what is interesting is the increasing interest and awareness. Many groups seem to be working on it now — partly because of their suitability for deep learning models (where people use all those deep ensemble type methods which are not valid). I suspect there might be real progress in a few years.
Very kind of you to make an effortpoast, thank you. I had seen a couple of these but must take an afternoon to go through the rest.
Here are a few that are quite recent really caught my eye (except for one). Also to underline that the area has been heating up.
On going beyond the usual exchangeability assumption (or variants of it, like weighted exchangeability).
– Conformal Prediction Going Beyond Exchangeability https://arxiv.org/abs/2202.13415
– Adaptive conformal inference under distribution shift https://arxiv.org/abs/2106.00170
– A Distribution-Free Test of Covariate Shift Using Conformal Prediction
https://arxiv.org/abs/2010.07147
– Split conformal prediction for dependent data https://arxiv.org/abs/2203.15885
– Distribution-free uncertainty quantification for classification under label shift https://arxiv.org/abs/2103.03323
– Doubly robust calibration of prediction sets under covariate shift https://arxiv.org/abs/2203.01761
Time Series:
– Conformal Time-series Forecasting https://openreview.net/forum?id=Rx9dBZaV_IP
– Adaptive conformal predictions for time series https://arxiv.org/abs/2202.07282
– CP with Temporal Quantile Adjustments https://arxiv.org/abs/2205.09940
What you were saying above in terms of “integrating over loss functions” has also started to be taken up. E.g.
– Training Uncertainty-Aware Classifiers with Conformalized Deep Learning
https://arxiv.org/abs/2205.05878
etc etc.
Forgive typos (and weird sentence constructions) — going to blame it on sleep deprivation. 🙂 Also I mean integrating over the confidence region, to get classifiers that have better uncertainty awareness.
Dito. Really nice collection of papers!!!! Thanks
I can’t tell you how grateful I am for these updates, but, like pretty grateful! Please keep them coming if you have the time.
Conformal prediction has moved a long way since this article, here is the most comprehensive resource on conformal prediction https://github.com/valeman/awesome-conformal-prediction
Thanks for writing this Valeriy. Somehow I didn’t see it when you posted.